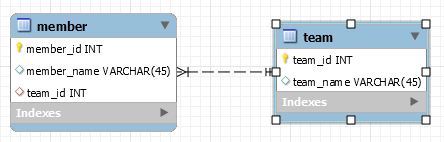
ManyToOne
다대일 관계의 반대 방향은 항상 일대다 관계이며 일대다 관계의 반대 방향도 다대일 관계다.
데이터베이스에서 일대다 관계에서 외래 키는 항상 다쪽이 가지고 있기 때문에
객체의 양방향 관계에서의 주인도 항상 다쪽이다.
양방향 연관관계는 항상 서로를 참조해야 한다.
setTeam, addMember 같은 편의 메서드를 작성하는 것이 좋지만
양쪽에 모두 작성하는 경우에는 무한루프에 빠질 수 있으니 검사해줘야 한다.
OneToMany
일대다 관계는 엔티티를 하나 이상 참조할 수 있어서 컬렉션 타입을 사용한다.
일대다 단방향 관계를 매핑할 때 @JoinColumn 어노테이션을 명시하지 않으면
연결 테이블을 중간에 두고 연관관계를 관리하는 조인 테이블 전략을 사용하여
반드시 명시해주는게 좋다.
일대다 단방향 매핑은 결국 외래키를 직접 가지고 있는 것이 아니기 때문에
연관관계 처리를 위한 UPDATE SQL을 추가로 실행해야 한다.
그래서 일대다 단방향 매핑은 반대 테이블의 외래 키를 관리해야 하기 때문에
성능과 관리적인 부분에서 좋지 않다.
일대다 단방향 매핑보다는 관리해야 하는 외래 키가 본인 테이블에 있는
다대일 양방향 매핑을 사용하는 것이 좋다.
OneToMany : ManyToOne (일대다 양방향)
다대일 양방향 매핑에서 연관관계의 주인은 항상 다쪽인 ManyToOne이기에
@ManyToOne 속성에는 mappedBy가 없는 것이다.
일대다 양방향 매핑을 사용할 일이 없지만 아래와 같이 매핑 할 수는 있다.
public class Team {
// 기존 코드 생략
@OneToMany
@JoinColumn(name = "TEAM_ID")
private List<Member> members = new ArrayList<Member>();
}
public class Member {
// 기존 코드 생략
@ManyToOne
@JoinColumn(name = "TEAM_ID", insertable = false, updatable = false)
private Team team;
}위의 코드처럼 양쪽 모두에 같은 외래키를 사용하게 매핑을 하는데
이때 다쪽의 외래키를 읽기 전용으로 만들어 양쪽에서 같은 외래키를 관리하지 못하게 한다.
일대다 양방향이라기 보단 반대쪽은 읽기 전용으로 만들기 때문에
일대다 단방향 매핑이 가지는 단점을 그대로 가셔서 다대일 양방향 매핑을 사용하는 것이 좋다.
OneToOne
한 명의 회원이 하나의 장바구니만 가지는 것과 같은 관계로
아래와 같은 특징을 가지고 있다.
- 일대일 관계에서는 반대 쪽도 항상 일대일 관계다.
- 둘 중 어느 곳이나 외래 키를 가질 수 있다.
일대일 관계는 둘 다 외래키를 가질 수 있기 때문에 누가 외래키를 가질지 지정해야한다.
주 테이블에 외래 키를 두는 방법
주 객체가 대상 테이블을 참조하는 것처럼 주 테이블(회원)이 장바구니를 참조한다.
외래키를 객체 참조와 비슷하게 사용할 수 있어서 객체지향 개발자들이 선호하며
주 테이블만 확인해도 연관관계를 확인 할 수 있다.
@Entity
public class Member {
// 기본 필드 생략
@OneToOne
@JoinColumn(name = "LOCKER_ID")
private Locker locker;
}
@Entity
public class Locker {
@Id
@GeneratedValue
@Column(name = "LOCKER_ID")
private Long id;
}위의 코드처럼 단방향으로 매핑하거나
@Entity
public class Locker {
// 기존코드 생략
@OneToOne(mappedBy = "locker")
private Member member;
}위의 코드처럼 양방향으로 매핑할 수 있다.
양방향 매핑이니 당연히 연관관계의 주인을 설정해줘야하는데
주 테이블인 멤버 엔티티의 외래키 컬럼을 주인으로 설정한다.
대상 테이블에 외래 키를 두는 방법
JPA에서는 일대일 관계에서 대상 테이블에 외래 키가 있는 단방향 관계를 지원하지 않기 때문에
대상 테이블에서 주 테이블로 단방향 관계를 수정하거나
양방향 관계로 만들고 대상 테이블을 연관관계의 주인으로 설정해야 한다.
@Entity
public class Member {
// 기본 필드 생략
@OneToOne(mappedBy = "member")
private Locker locker;
}
@Entity
public class Locker {
// 기본 필드 생략
@OneToOne
@JoinColumn(name = "MEMBER_ID")
private Member member;
}위와 같이 일대일 매핑에서 대상 테이블에 외래키를 두기 위해선
양방향으로 설정한 후에 연관관계의 주인을 주 테이블이 아닌
대상 테이블로 설정한다.
ManyToMany
관계형 데이터베이스에서는 테이블 2개로 다대다 관계를 표현할 수 없기 때문에
다대다 관계를 다대일 관계로 풀어내는 연결 테이블을 사용하지만
객체는 테이블과 다르게 객체 2개로 다대다 관계를 만들 수 있다.
단방향
@Entity
public class Member {
// 기본 필드 생략
@ManyToMany
@JoinTable(name = "MEMBER_PRODUCT", joinColumns = @JoinColumn(name = "MEMBER_ID"),
inverseJoinColumns = @JoinColumn(name = "PRODUCT_ID"))
private List<Product> products = new ArrayList<Product>();
}위와 같이 @ManyToMany 어노테이션을 사용하여 다대다 단방향 관계를 설정할 수 있으며
@JoinTable 어노테이션을 사용하여 연결 테이블을 바로 매핑할 수 있다.
@JoinTable의 속성은 아래와 같다.
- name : 연결 테이블을 지정
- joinColumns : 현재 방향인 회원과 매핑할 조인 컬럼 정보를 지정 (회원 테이블의 기본키)
- inverseJoinColumns : 반대 방향인 상품 테이블과 매핑할 조인 컬럼 정보를 지정 (상품 테이블의 기본키)
양방향
@Entity
public class Product {
// 기본 필드 생략
@ManyToMany(mappedBy = "products")
private List<Member> members;
}반대쪽 엔티티에도 매핑을 해주면 양방향 관계로 설정할 수 있다.
양방향 연관관계 편의 메서드
member.getProducts().add(product);
product.getMembers().add(member);위와 같이 연관관계를 설정해주는 반복적인 작업들을
아래 코드와 같이 주 테이블에 메서드로 만들어 편리하게 사용하는 것이 좋다.
@Entity
public class Member {
// 기존 코드 생략
public void addProduct(Product product) {
products.add(product);
product.getMembers().add(this);
}
}
member.addProduct(product);@ManyToMany 어노테이션을 사용한 매핑의 단점
어노테이션을 사용하여 연결 테이블을 자동으로 매핑하면 편리하지만
관계를 맺는 양쪽 테이블의 기본키만 외래키로 가지고 있기 때문에
추가적인 컬럼이 필요한 경우 추가할 수가 없다.
그래서 N:M 관계를 직접 연결 테이블을 추가하여 매핑하는 것이 좋다.
만약 회원과 주문이 N:M 관계라면
회원N : M주문 >> 회원1 : N:연결 테이블M : 1주문 형태로 바꿀 수 있다.
@Entity
public class Member {
@OneToMany(mappedBy = "member")
private List<MemberProducts> memberProducts;
}
@Entity
@IdClass(MemberProductId.class)
public class MemberProduct {
@Id
@ManyToOne
@JoinColumn(name = "MEMBER_ID")
private Member member;
@Id
@ManyToOne
@JoinColumn(name = "PRODUCT_ID")
private Product product;
}
@Entity
public class Product {
@OneToMany(mappedBy = "product")
private List<MemberProducts> memberProducts;
}위의 코드는 다대다 양방향 관계를 코드로 표현한 예시다.
만약 회원상품 엔티티처럼 복합 키를 사용하는 경우에는
식별자 클래스가 추가로 필요하다.
public class MemberProductId implements Serializable {
// 회원멤버 엔티티의 member / product와 연결
private String member;
private String product;
// hashCode, equals 메서드 오버라이딩 하기
}위의 코드처럼 복합 키는 별도의 식별자 클래스를 사용해서 만들어야 하며
Serializable을 구현하여야 하며 hashCode, equals 메서드를 구현해야 하고
기본 생성자가 있어야 하며 해당 클래스는 public이어야 한다.
@Entity
public class Order {
@Id
@GeneratedValue
@Column(name = "ORDER_ID")
private Long id;
@ManyToOne
@JoinColumn(name = "MEMBER_ID")
private Member member;
@ManyToOne
@JoinColumn(name = "PRODUCT_ID")
private Product product;
}복합 키를 사용하는 방법은 번거롭기 때문에 위의 코드처럼
별도의 기본 키를 사용하는 것이 편하다.
실습
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "MEMBER_NAME")
private String name;
@Column(name = "MEMBER_CITY")
private String city;
@Column(name = "MEMBER_STREET")
private String street;
@Column(name = "MEMBER_ZIPCODE")
private String zipcode;
@OneToMany(mappedBy = "member")
private List<Order> orders = new ArrayList<Order>();
}
@Entity
@Table(name = "ORDERS")
public class Order {
@Id
@GeneratedValue
@Column(name = "ORDERS_ID")
private Long id;
@ManyToOne
@JoinColumn(name = "MEMBER_ID")
private Member member;
@OneToOne
@JoinColumn(name = "DELIVERY_ID")
private Delivery delivery;
@Column(name = "ORDERDATE")
private LocalDateTime orderDate = LocalDateTime.now();
@Enumerated
@Column(name = "ORDERS_STATUS")
private OrderStatus status = OrderStatus.ACTIVE;
public enum OrderStatus {
ACTIVE,
STOP
}
}
@Entity
public class Delivery {
@Id
@GeneratedValue
@Column(name = "DELIVERY_ID")
private Long id;
@Column(name = "DELIVERY_CITY")
private String city;
@Column(name = "DELIVERY_STREET")
private String street;
@Column(name = "DELIVERY_ZIPCODE")
private String zipcode;
@Enumerated(EnumType.STRING)
@Column(name = "DELIVERY_STATUS")
private DeliveryStatus status = DeliveryStatus.START;
public enum DeliveryStatus {
START,
END
}
}
@Entity
public class OrderItem {
@Id
@GeneratedValue
@Column(name = "ORDER_ITEM_ID")
private Long id;
@ManyToOne
@JoinColumn(name = "ORDER_ID")
private Order order;
@ManyToOne
@JoinColumn(name = "ITEM_ID")
private Item item;
@Column(name = "ORDERPRICE")
private int orderPrice;
private int count;
}
@Entity
public class Item {
@Id
@GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
@Column(name = "ITEM_NMAE")
private String name;
@Column(name = "ITEMPRICE")
private int itemPrice;
private int stockQuantity;
}
@Entity
@IdClass(CategoryItemId.class)
@Table(name = "CATEGORY_ITEM")
public class CategoryItem {
@Id
@ManyToOne
@JoinColumn(name = "ITEM_ID")
private Item item;
@Id
@ManyToOne
@JoinColumn(name = "CATEGORY_ID")
private Category category;
}
public class CategoryItemId implements serializable {
private String item;
private String category;
@Override
// equals 및 hashCode 오버라이딩
}
@Entity
public class Category {
@Id
@GeneratedValue
@Column(name = "CATEGORY_ID")
private Long id;
}'Back-End > JPA' 카테고리의 다른 글
| 연관관계 매핑 기초 (0) | 2023.06.20 |
|---|---|
| 엔티티 매핑 : 학습을 위한 스키마 자동 생성하기 (0) | 2023.06.19 |
| 엔티티 매핑 : 매핑 어노테이션 (0) | 2023.06.19 |
| 영속성과 엔티티 (0) | 2023.06.01 |
| JPA 시작하기 (0) | 2023.06.01 |